
Forta is the standard for real-time detection networks for security & operational monitoring of blockchain activity. As a decentralized monitoring network, Forta detects threats and anomalies on DeFi, NFT, governance, bridges and other Web3 systems in real-time.
Funds lost in smart contract exploits in 2020: $215M
Funds lost in smart contract exploits in 2021: $1.3B
Funds lost in smart contract exploits in 2022: $2.7B
This is a problem, and it isn’t going away.
The current approach to smart contract security centers around code, and it’s evident in the way projects allocate their security budgets. Audits assess code. Formal verification proves code behaves correctly. Bug bounties incentivize white hats to report bugs in the code.
The focus on code is well placed, and rooted in DeFi’s desire to be “hands off”. But as 2022 losses confirm, even an obsessive focus on code quality can’t eliminate exploits. In fact, many exploits have nothing to do with your code at all – they are market driven, prey on dependencies outside your control (i.e. third party oracles), or involve compromised Web 2 components (private keys, front ends, APIs). A hands off approach just doesn’t work.
If Web 3 wants to prevent exploits, it needs a comprehensive security approach that prioritizes threat detection and prevention. You need to be able to identify malicious activity in real-time, and respond swiftly. You need to be hands on.
A year ago, no one was doing real-time threat detection (except a few auditors doing it internally). This was due in part to project teams not having full-time security people on staff. It wasn’t anyone’s job. If someone did want to do it though, a lack of detection tools made it difficult. You basically had to build your own threat detection system from scratch.
Today with the help of Forta, real-time threat detection solutions are available and more teams are actively monitoring. Detection precision and recall is increasing, and machine learning is having a big impact. But detection is only half the battle. To prevent an exploit, good detection tools must be accompanied by good prevention mechanisms. This is where the collective “we” fall short.
On numerous occasions Forta has flagged an exploiter contract before the exploit, but the victim protocol couldn’t block the malicious transaction or pause the system fast enough to prevent the attack. We also asked over a dozen protocols – some large, some small – what they would do with five minutes advance notice of an exploit. Every team said “we can’t do anything that fast”.
Web 3 is outgunned, plain and simple. We need new, faster and more surgical threat prevention measures, and we need them now. Five minutes is an eternity.
It’s time to level up.
Current State of Threat Prevention
Faced with an imminent exploit today, projects generally have one prevention measure at their disposal – pause the protocol. Pause functionality is usually triggered by a multisig composed of several independent people, often in different locations and time zones.
According to research conducted by Imperial College of London on over 180 smart contract exploits between 2018 and 2022, approximately 50% of exploited protocols had pause functionality in their contracts. Unfortunately the average time to invoke a pause was over 24 hours. Too slow to prevent the attack.
Speed isn’t the only issue with current pause functionality. Because pause buttons usually pause everything, it means a complete shutdown of service, even for legitimate users. This is the equivalent of a bank stopping all transaction processing in response to one fraudulent check. One bad actor/transaction shouldn’t completely degrade the user experience for everyone else.
What should the future of threat prevention look like?
The Future of Threat Prevention
First off, there is no one-size-fits-all solution to prevent threats. There are a variety of approaches at different layers of the tech stack, and there are pros and cons to each. Protocols should choose solutions (likely more than one) that best meet their risk appetite and their users’ expectations. Transparency will be key, so users can make informed decisions.
Some factors to consider when evaluating threat prevention measures:
– Cost: how does a threat prevention solution raise costs for end users to interact with the protocol?
– User Friction: how does a threat prevention solution impact users ability to interact with the protocol? Are there false positives (FPs) that would bar legitimate users? Are there potential negative impacts to composability? What is the FP mitigation strategy? How costly and fast is such an FP mitigation strategy?
– Composability: what is the impact on composability? Does a solution make it more difficult or costly for a complimentary protocol or user to integrate?
– Complexity: how does a threat prevention solution impact the overall complexity of the protocol? Does the increased complexity make the protocol more difficult to maintain, or more susceptible to an attack?
– Decentralization: Who is entrusted with decision making? Is this a centralized entity that becomes a single point of failure? Will there be several threat prevention services available that protocols can choose from? Is there going to be a standard that allows protocols to switch easily from one service to another?
– Censorship: certain threat prevention solutions, e.g. a transaction filter, could be viewed as a censorship layer (if centralized, could this entity be compelled to expand its scope beyond security assessments). In what layer of the stack should it reside to facilitate user choice? Is such a filtering mechanism culturally acceptable for the protocol, their users, and web3 overall?
– Effectiveness/ Robustness: How effective is the threat prevention layer in preventing attacks? How robust and resistant is it if an attacker attempts to attack or game the threat prevention solution?
– Availability: Is the solution available now, in the near term (within a year) or the long term (1+ year), and what is required for adoption?
With these considerations in mind, let’s look at some alternatives.
Preventative
Preventative solutions are designed to prevent attacks. This could be accomplished through different custodial models (effectively reducing the risk profile of a protocol) or transaction screening, such that exploit transactions are first assessed/simulated and potentially rejected before they are mined.
1. Asset Segregation
One reason why smart contract exploits involve such large amounts is because DeFi assets are usually in large on-chain liquidity pools. Take a bridge for example – 100% of the bridge’s liquidity is managed by smart contracts akin to an omnibus account. It’s DeFi’s version of a hot wallet and bridges are massive honey pots for hackers as a result.
In CeFi, crypto exchanges segregate assets between hot and cold wallets. On average, the split is roughly 95-98% cold, 2-5% hot, where the percentage in hot wallets represent the minimum necessary to meet daily withdrawal activities, perhaps with a small buffer. Assets in cold storage don’t move very frequently, and the process for withdrawing those assets is more cumbersome by design.
Could DeFi and bridges benefit from having a majority of assets segregated or stored in a more secure way? Probably. It adds some complexity, but it also lowers a project’s risk profile. This would require projects to understand their daily operational liquidity requirements, and develop new processes for asset segregation. It may also introduce user friction in the form of withdrawal delays, but this feels like a reasonable trade off in most cases.
One open and interesting question is the difficulty of segregating assets where zk rollups are involved. Settlement to Ethereum is dependent on the verifier contract and the prover, and decoupling the state of a rollup to a few different contracts may introduce challenges.
In spite of these considerations, we think asset segregation is one of the more promising risk prevention measures.
2. Transaction Screening
If a bank sees a large credit card transaction from an unusual location or in an unusual amount, the transaction is subjected to additional scrutiny and a secondary verification is made, such as a phone call or text message to the cardholder. We believe there would be a benefit to screening and slowing down suspicious on-chain transactions in a similar fashion.
Before we discuss the mechanics of a transaction screening solution, we want to acknowledge the importance of maintaining censorship resistance at the base layer. Any approach that impacts a transaction’s ability to be included in a block and processed should receive a healthy amount of scrutiny. That said, we think transaction screening at both the base layer and the application layer warrant discussion in this context.
Transaction screening can be separated into two approaches: negative and positive reputation
– Negative reputation identifies malicious behavior in the transaction and disallows that transaction, but allows all other transactions. This could be accomplished through pre-mining simulation or through a broad range of heuristics/machine learning models to assess whether the transaction is likely malicious.
– Positive reputation flips the approach on its head and essentially deems all transactions as suspicious unless they can demonstrate they aren’t. This could be accomplished, for instance, by assessing the transaction history of an account, whether the account was funded through an exchange with stringent KYC processes, etc. A crucial aspect of a positive reputation system will be its coverage and how many legitimate users would be negatively impacted.
If transaction screening was implemented at the builder/relayer layer – when a block is built – it represents a blanket assessment for every transaction and could constitute censorship without leaving users a choice (other than moving to a different chain). Another perhaps more palatable variation would be to have transaction screening at the builder/relayer level but allow protocols to “opt in” to the screening (so it is not “blanket”). Even within a single protocol, some pools/vaults might opt in to screening, others might not, allowing users to self-select.
If communities are uncomfortable doing any screening at the base layer, screening at the application layer is another alternative. Each protocol can make a business decision about how much friction and risk they are comfortable with. Transaction screening could be applied selectively to a subset of transactions, such as large value transactions, similar to how a bank or financial services platforms screens today. Further, a block action on a screened transaction could also be more nuanced. For instance, instead of a block, a transaction could be placed in a time lock.
Another variation of “screening” at the application level involves a “co-signer” – certain high risk transactions need a second signer to be approved. The second signer could be a person or entity with knowledge about the transaction or sender, or have legal liability if the transaction turns out to be malicious. The co-signer role essentially acts like a decentralized, external compliance team on a transaction by transaction basis.
3. Time Delays and Simulation
For activity above a certain amount threshold, it may be prudent to impose a mandatory delay on the transaction. This would give a protocol enough time to simulate the transaction to determine whether the result is malicious or benign. As an example, imagine you are withdrawing $5M from a bridge. This amount exceeds the threshold, requiring that the withdraw be delayed and the transaction simulated. If the transaction is legitimate, it is approved and processed immediately after the delay period is over. If the transaction is malicious, it is blocked.
This logic can be implemented using smart contracts, similar to the timelock features commonly found in DAOs). This leaves the project (and the community) enough time to automatically screen the transaction, while at the same time does not affect most transactions, since most swap/bridge activity would not trigger the delay.
Mitigative
Mitigative techniques aim to reduce the impact of attacks. This could be accomplished by frontrunning the exploit and transferring assets to a safe haven or by implementing automated circuit breakers into the protocol.
1. Frontrunning exploits
In the absence of strong prevention mechanisms, front-running exploit transactions has been a popular approach for some white hats. This involves detecting an exploit transaction in the public mempool and initiating an identical transaction with a higher gas fee such that the duplicate transaction receives priority processing. Instead of sending funds to the hacker, a white hat sends funds to a safe haven with the intention of returning them to the victim. Teams like Blocksec have developed a speciality in this area and have had success beating hackers to the punch.
However, with the proliferation of Flashbots and private mempools, white hats have decreased visibility into pending transactions. The introduction of ZKPs and other privacy technologies, as well as the growth of high-rate L2s with minimized or non-existent mempools, will further compound transaction visibility challenges. Without coordination from block builders and relayers, the days of front running exploits are likely coming to an end.
2. Automated Circuit Breakers
Smart contract pause functionality is similar to a stock exchange circuit breaker. The main difference is pause functionality must be manually triggered today, whereas circuit breakers are automatically triggered based on market conditions – usually a certain intraday percentage price drop.
Introducing automation into Web 3’s threat prevention process is important because every second matters. Automated pause functionality that triggers based on high-confidence Forta alerts, for example, could pause the protocol fast enough to actually prevent an attack.
Key questions for this approach include what are you pausing, and how is the pause function invoked? Pause functionality can apply to the entire protocol, or only to a specific module, feature, pool or asset. In almost every case, a more surgical pause strikes a better balance between managing risk and introducing friction for legitimate users. The problem with most pause functions today is they are a giant hammer, stopping the protocol for bad actors and all legitimate users as well.
Two variations of automated circuit breakers that are perhaps more achievable in the short term are (a) speeding up the current multisig signing process, and (b) introducing a temporary pause. Imagine a transaction invoking the pause function is pre-signed by the multisig, completely or partially. A high-confidence Forta alert then either (a) triggers a fully signed transaction to be broadcast, or (b) alerts the remaining multisig signers.
In the second variation, a high-confidence Forta alert can unilaterally trigger a temporary pause (i.e. one hour) until the multisig can take formal action.
In all cases, implementing automation must be thoughtful. Assuming the logic/process is public, it is subject to manipulation by bad actors. It is also subject to manipulation by competitors who could DDOS the protocol, intentionally degrading the user experience.
Reactive
Lastly, reactive measures act after the attack has taken place to recover losses.
1. Transaction Reversibility
After an exploit, protocols are often able to recover some or all of the stolen funds by either negotiating with the hacker or working with centralized exchanges and asset issuers to blacklist stolen funds. This is what we’ll refer to as “off-chain reversibility” because it’s a very manual process.
While these post-exploit efforts can prove fruitful, teams should not rely on the ability to negotiate and clawback funds. It doesn’t work in every case. The approach isn’t particularly user friendly either. If the victim protocol allows the hacker to keep a percentage of the funds as a “bounty”, then users funds are paying the bounty, not the team (unless users are subsequently reimbursed by the protocol). This arrangement doesn’t incentivize the right behavior from the protocol team.
There are some “on-chain reversibility” approaches too. Researchers at Stanford University recently released a paper proposing new ERC20 and ERC721 token standards that feature reversible functionality centered around challenge periods (akin to a transaction-specific statute of limitations).
These approaches deserve consideration, though we have a preference for preventing the loss entirely. It’s likely that some reversibility features end up being paired with other preventative and mitigative measures.
2. Cyber Insurance
As a last resort, cyber insurance like that offered by Sherlock and Nexus Mutual could be utilized to reduce the impact of an attack. Web3 has the advantage that transactions, the protocol itself, and attacks are public, which leads to effective assessment of risk and associated cyber insurance premiums. Cyber insurance could be one way to secure user funds in a completely censorship resistant manner (not implementing any other threat prevention strategies outlined above), albeit likely at a higher premium. However, underwriting appetite isn’t likely to grow significantly until there is more historical data and better risk prevention/mitigation measures in place. The risk is simply too high.
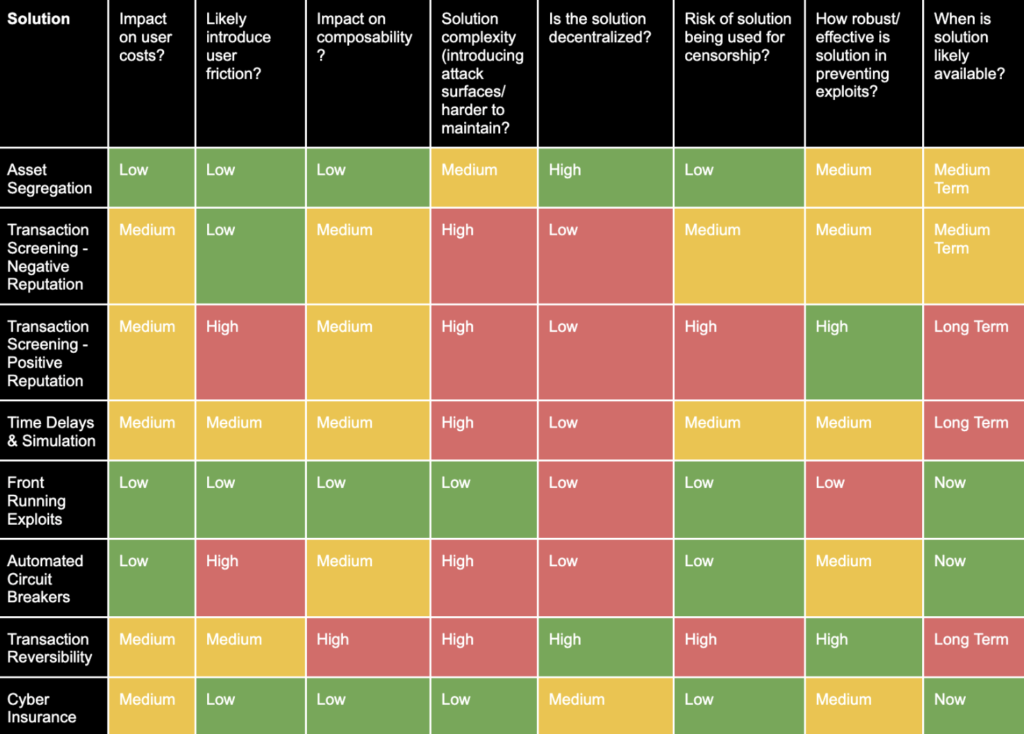
Web3 is in need of threat prevention solutions that prevent, mitigate, and reactively respond to attacks. An initial assessment based on the factors is outlined in the table above; design and implementation will likely influence these significantly. However, what can be gleaned from the assessment are different solutions that may appeal to different entities. For instance, a protocol that values censorship resistance may invest more resources in post-exploit mitigation measures like transaction reversibility and cyber insurance. For protocols that are courting institutional liquidity and need a highly effective and robust solution, they may opt to implement positive reputation based transaction screening.
In any case, many considerations need to be made when designing these solutions. Transparency on what a protocol adopts and the consequences of such solutions are key so users effectively have a choice that matches their risk profile. This blog post outlined a few possible directions and hopefully inspires a vibrant discussion to further refine these approaches. Join the Forta forum/discord to discuss pros/cons, share your perspective, define standards, and ultimately prototype solutions. Web3 needs it.
A special thanks to Yajin Zhou (Blocksec), Jonathan Alexander, Michael Lewellen, Juan Bautista Carpanelli (OpenZeppelin), Idan Levin (Collider Ventures), Mehdi Zerouali and Adrian Manning (Sigma Prime), Hart Lambur (UMA); Yaniv Sofer (EY), Jack Sanford (Sherlock), Sam Ragsdale (a16z), Dmitry Gusakov (Lido), Kasper (Euler) and Chris von Hessert (Polygon) for feedback and helping shape the perspective on this topic.
 Share post
Share post